
MobileNet
MobileNets是为移动和嵌入式设备提出的高效模型,最核心的idea是depthwise separable convolution,并在此基础上引入了两个全局超参数控制模型规模和相关的latency-accuracy trade-off。
Related Work
由于CNN的广泛应用,对设计和训练高速/小型CNN的兴趣在不断的增长中。在建立小型高效的神经网络工作中,通常可分为两类:
- 一个是将训练好的大规模网络做“压缩”或者“修剪”,代表工作是DeepCompression;
- 另外一个路径是从头开始训练一个特别设计的网络结构。相关工作包括:Flattened networks; Factorized networks; Xception network等等。另外还有一个训练小网络的方法是distillation。
Architecture
Depthwise Separable Convolution
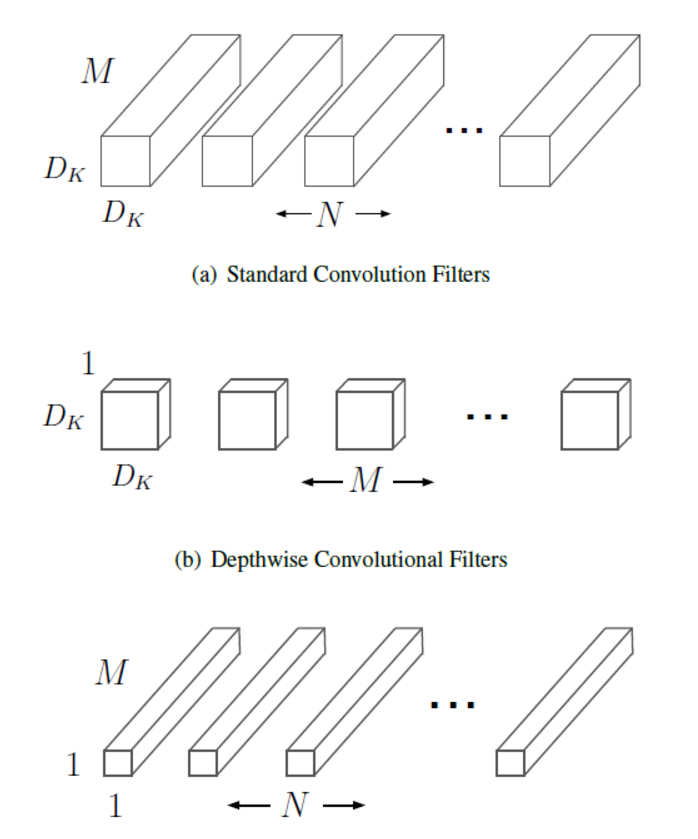
MobileNets的核心idea是depthwise separable convolution,简单的说就是把一个k*k*M*N(空间上是k*k,M是输入channel数,N是输出channel数)替换成:
Filtering部分的depthwise卷积:M个k*k*1的2D卷积,输出channel数保持为M不变
Combining部分pointwise卷积:N个1*1*M的卷积,输出channel数为N
depthwise卷积层和pointwie卷积层都是有BN和ReLU。两个卷积层之间非线性变换的引入使得MobileNets不是严格的在做卷积核的factorization。
相比标准的kkM*N卷积网络,计算量的变化是:
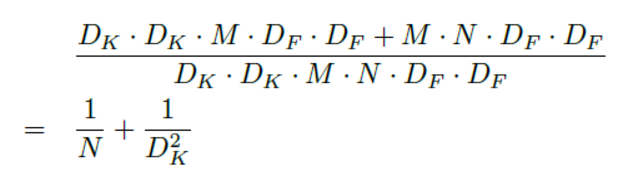
由于一般DK=3而N>>10,所以后面一项较大,我们可以得到接近9倍的提速。
Network Structure and Training
基于depthwise separable convolution,我们可以构建MobileNets,基本单元如下图右侧:

降采样只发生在depthwise卷积层,而不会发生在pointwise卷积层。
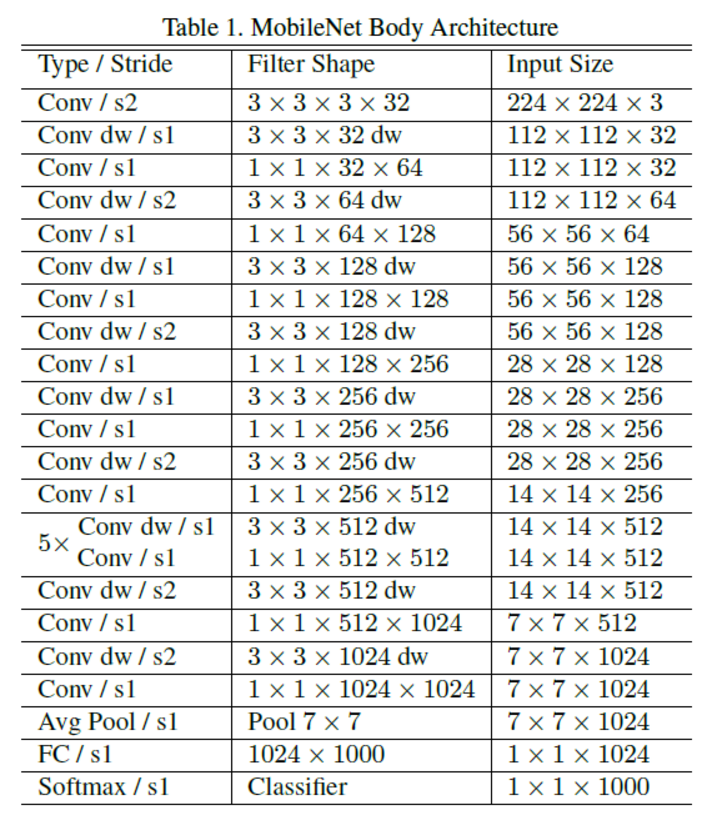
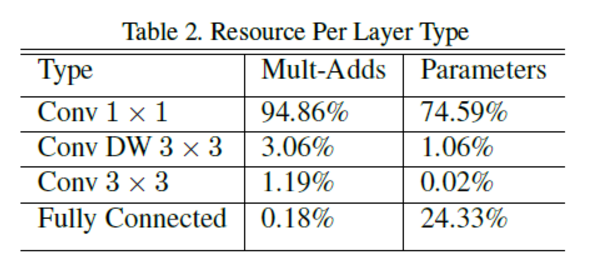
另一个depthwise separable convolution的好处是实现的效率,1*1卷积在输入输出channel数分别为M和N的时候,等价于乘以一个M*N的矩阵,是有高度优化的GEMM实现的。另外一点是1*1卷积而不需要k*k卷积在k>1时候的im2col操作,基本全部时间都在做计算。MobileNets的95%的计算量和75%的参数在1*1卷积层。
Width Multiplier: Thinner Models
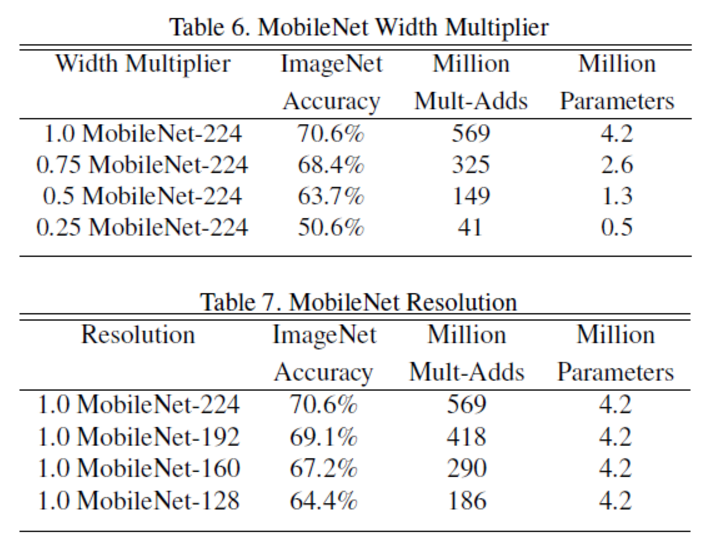
第一个控制模型大小的超参数是:宽度因子α (Width multiplier ),其实应该叫depth multiplier,是一个应用在全部卷积层深度上的一个系数, 用于控制输入和输出的通道数,即输入通道从M变为αM,输出通道从N变为αN, α∈(0,1],通常取1,0.7,0.5,0.25.
计算量减少了:
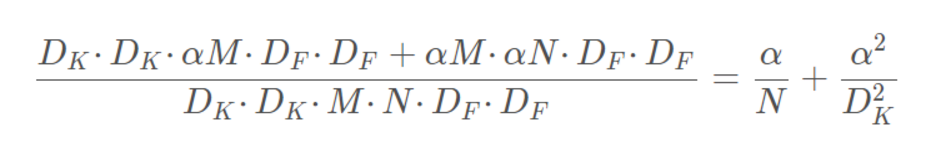
宽度因子将计算量和参数降低了约α^2倍,可很方便的控制模型大小.
Resolution Multiplier: Reduced Representation
我们引入的第二个控制模型大小的超参数是:分辨率因子ρ, 改变的是输入的长宽,整体计算量减少了:
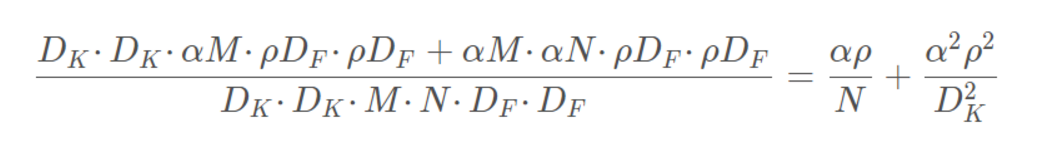
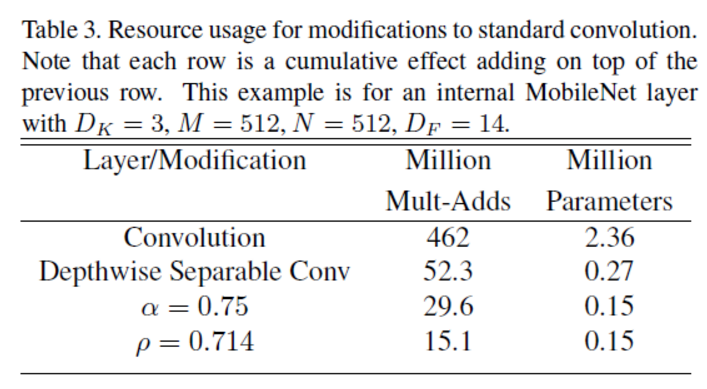
下面的示例展现了两个因子对模型的影响:
Experiments
Model Choices
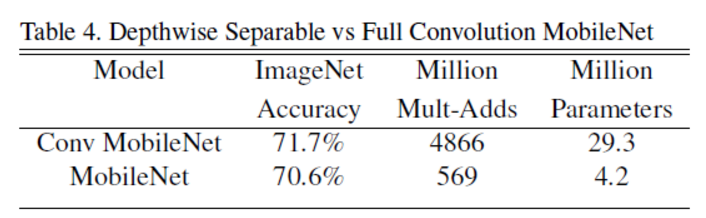
使用深度分类卷积的MobileNet与使用标准卷积的MobileNet之间对比 : 在精度上损失了1%,但是的计算量和参数量上降低了一个数量级。
使用width multiplier控制模型大小比直接使用浅层模型效果更好:
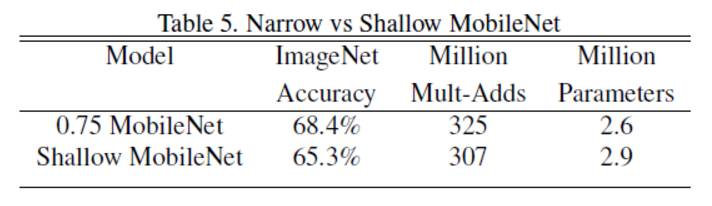
Model Shrinking Hyperparameters
改变alpha和rho都可以调节accuracy-computation trade-off
Conclusions
- MobileNet使用depthwise separable convolution有效的降低了模型的计算量和参数数量,在对等的卷积层上(1*3*3+1*1*N vs. 标准M*3*3*N),计算量和参数数量都有8-9倍的减少,代价是训练时的内存需求上升。
- 这篇文章并不是提出了一个新的网络结构MobileNets,而是证明了depthwise separable convolution的实用性,它可以使用在Inception结构中,也可以用在ResNet里
- 引入的两个全局超参数alpha和rho,和MobileNets关系不大,也可以用在其他的CNN中。只是提供了简单粗暴的方法控制模型规模,并没有考虑对性能的影响
- 这篇文章的贡献在于提供了一个训练高速网络的途径,它的意义在于:
- 加快模型迭代速度,研究者可以探索更多不同的网络结构,做prototyping。
- 应用CNN在移动端和嵌入式场景,接近一个量级的提速和模型压缩,只付出很小的性能的代价